A Roadmap from LLaVA-1.5 to Imp
A Roadmap from LLaVA-1.5 to Imp
The development of highly capable language models like LLaVA-1.5 has demonstrated the potential of leveraging large-scale curated datasets to achieve impressive performance in various natural language understanding and generation tasks. LLaVA-1.5, a 7 billion parameter language model, exemplifies this by achieving state-of-the-art results through a sophisticated architecture and extensive training regimen. However, deploying such large models in real-world applications often poses challenges related to computational resource constraints and latency requirements. To address these issues, there is a pressing need to explore more efficient models that can maintain competitive performance while being more resource-friendly. Our research is driven by the need to bridge this gap. We aim to develop a smaller yet highly capable model, derived from LLaVA-1.5, that can offer similar benefits in a more efficient manner. Specifically, we introduce the Imp-3B model, a streamlined version of LLaVA-1.5, designed to retain the advantages of its larger predecessor while being more suitable for practical deployment. This study meticulously examines the design space of language models, focusing on model architecture, training strategies, and data utilization to mitigate the performance degradation typically associated with model downsizing. Through a comprehensive analysis and a detailed roadmap, we illustrate how to achieve an optimal balance between model size and capability, ultimately contributing to the advancement of accessible and efficient language modeling.
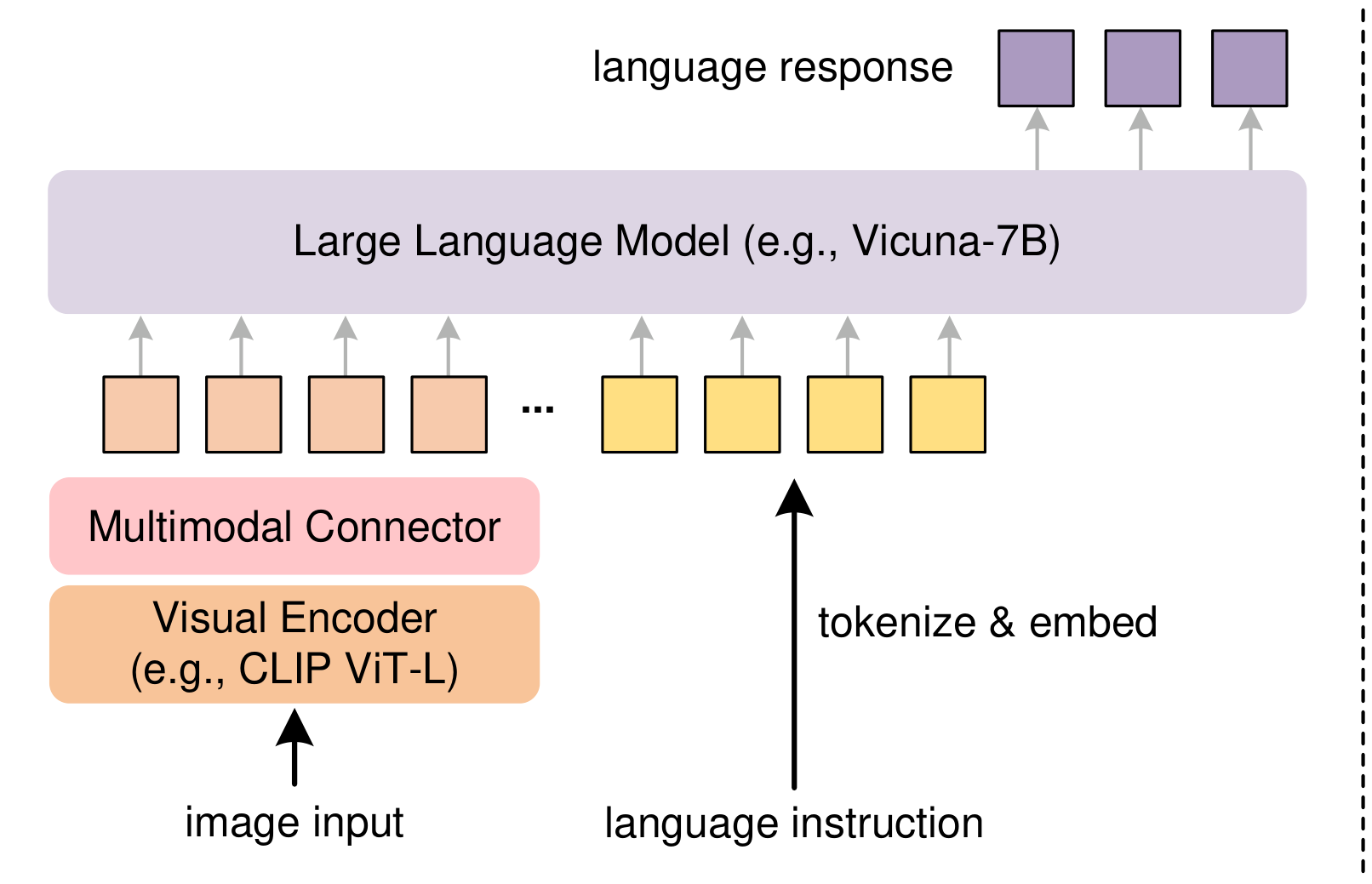
1. Optimized Model Architectures
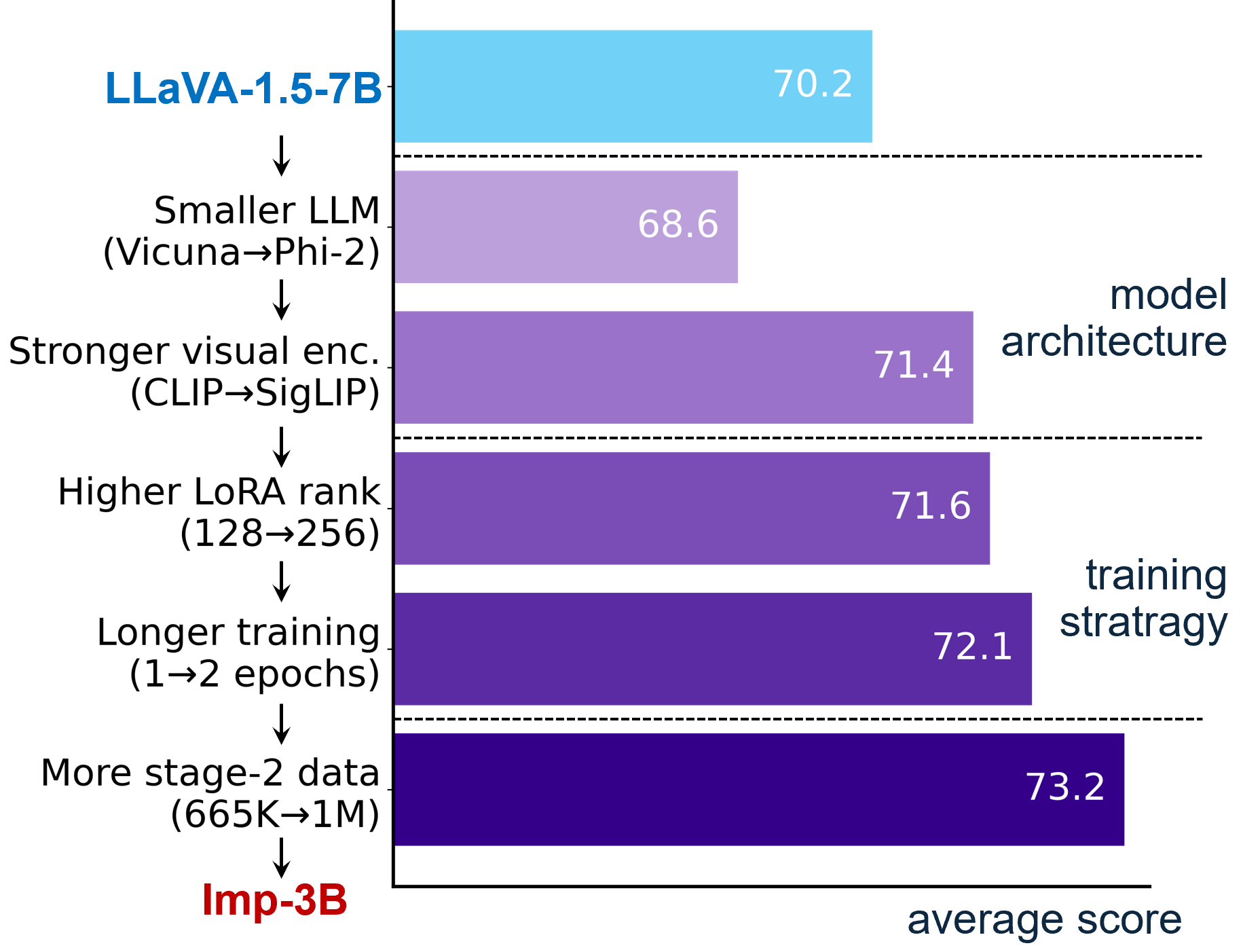
- Choice of the LLM. We find that the LMM's performance is highly dependent on its supporting LLM. Simply replacing the LLM with a more lightweight one leads to worse performance. What's more, conditioning on the same model scale, Phi-2 is superior to other choices, like MobileLLaMA, due to its meticulously organized training data.
- Choice of the visual encoder. A stronger visual encoder would yield a LMM with better vision-language capabilities. We verify that visual encoders trained with vision-language contrastive learning can obtain better visual representations than those pre-trained with ImageNet classification. We choose a strong visual encoder, SigLIP-SO/400M, as the visual encoder.
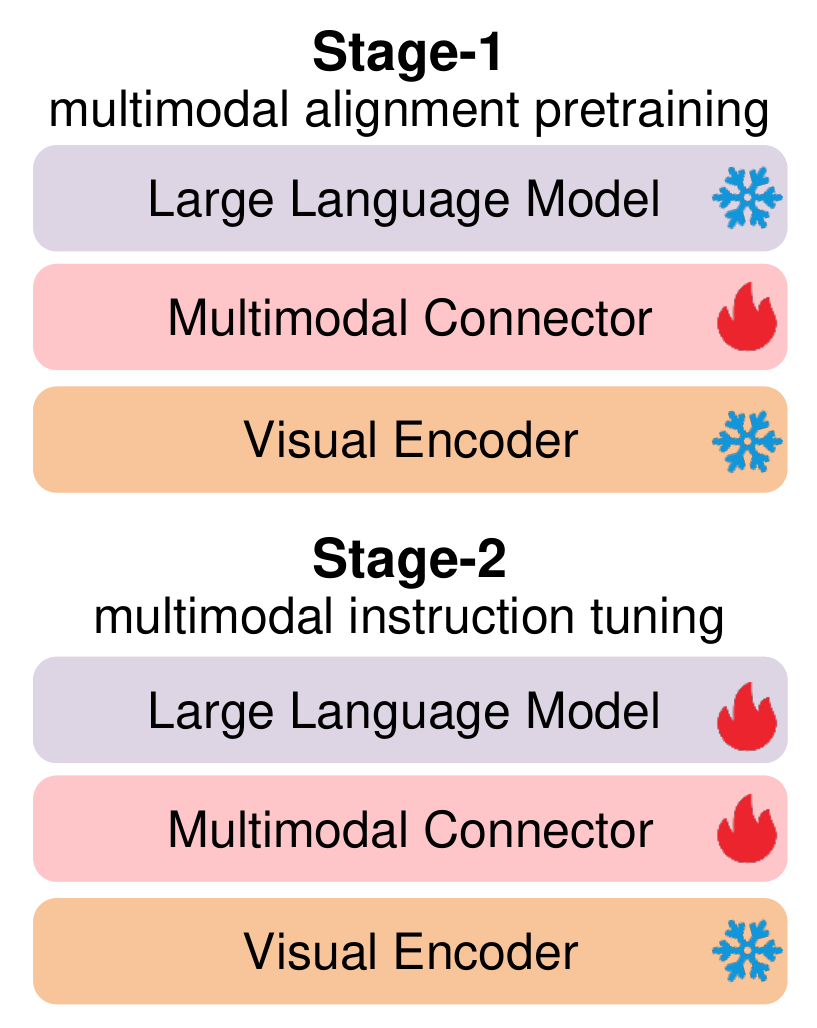
2. Improved Training Strategies
We follow LLaVA-1.5's two-stage training procedure, while exploring training strategies for lightweight LMMs. As the first stage only acts as an initialization, it is of less importance compared to the second stage. Therefore, we maintain the first-stage training settings in LLaVA-1.5.- Finetuning mechanism. We observe that the model trained with full-parameter funetuning is inferior to the models with LoRA finetuning. For LoRA finetuning, increasing rank from 128 to 256 brings a 0.2 point average score improvement, while further increasing it to 512 leads to a 0.1 point decrease. Therefore, we finetune the LMMs with LoRA of rank 256.
- Number of training epochs. Increasing training epochs from 1 to 2 brings a 0.5 point improvement in average score. Meanwhile, further increasing training epochs from 2 to 3 leads to a 0.4 point decrease. Because of these, we set the number of training epochs to 2.
3. Augmented Instrucion-following Data
We remove the 22K TextCaps dataset which uses the same set of training images as TextVQA to ensure more strict zero-shot evaluation. Training on this augmented instrucion-following dataset, we further improve the performance of the lightweight LMMs.
 Table 1. Statistical information of the instruction tuning dataset for Imp. Based on LLaVA's original 665K data, we remove the TextCaps dataset in line with and then append about 32K OCR & chart-oriented datasets and 330K GPT4V-annotated datasets, resulting in 1M mixed instruction-tuning data in total.
Table 1. Statistical information of the instruction tuning dataset for Imp. Based on LLaVA's original 665K data, we remove the TextCaps dataset in line with and then append about 32K OCR & chart-oriented datasets and 330K GPT4V-annotated datasets, resulting in 1M mixed instruction-tuning data in total.
 Performance
Performance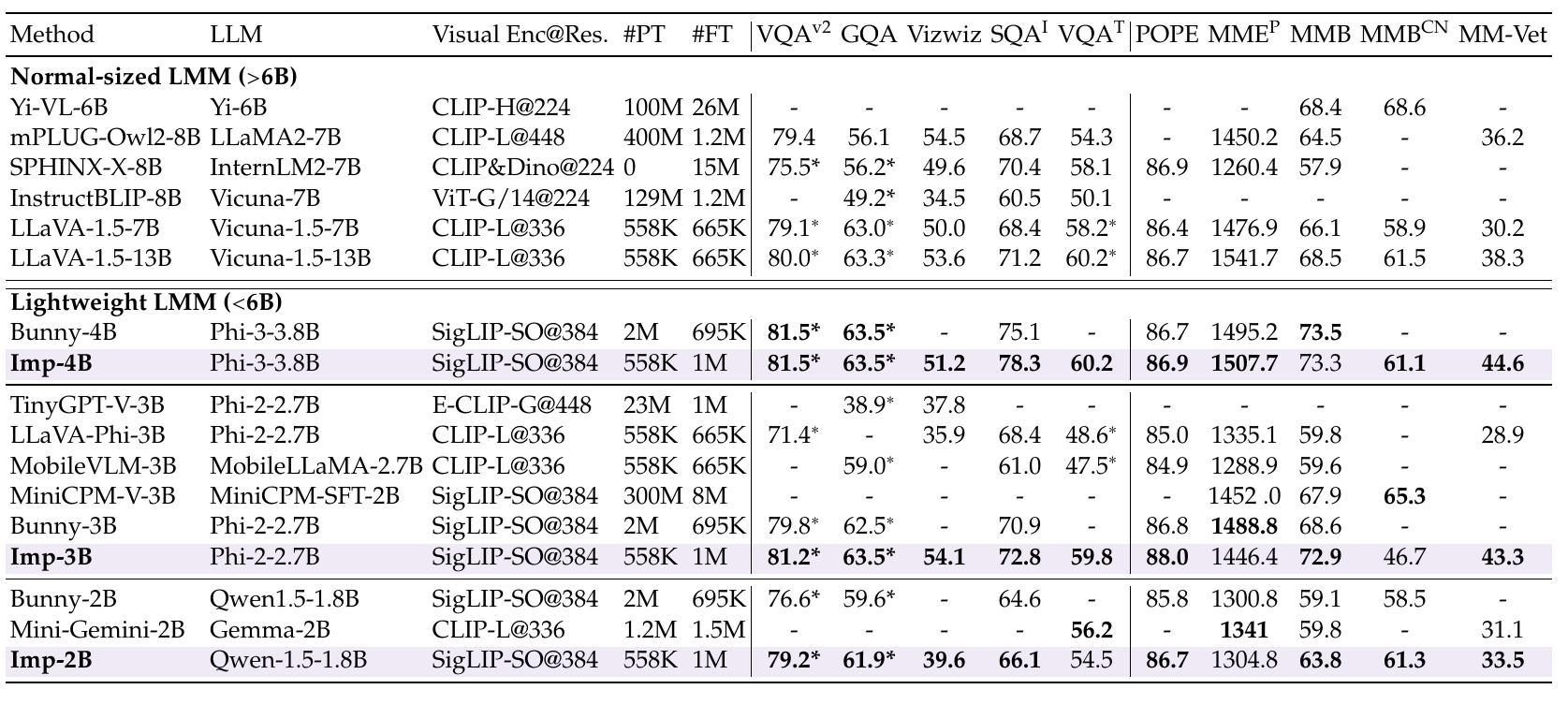 Table 2. Comparison of our Imp models (with purple backgrounds) and open-sourced stateof-the-art LMMs on ten commonly-used VQA and LMM benchmarks. #PT and #FT denote the number of pretrainng and instruction-tuning samples, respectively. Benchmark names are abbreviated due to space limits: VQA-v2; GQA; VisWiz; SQAI: ScienceQA-IMG; VQAT: TextVQA; POPE; MMEP: MME-Perception; MMB: MMBench (dev); MMBCN: MMBench-Chinese (dev); MM-Vet . *: The training images of the datasets are observed during training. The compared LMMs are first categorized into the normal-sized and lightweight groups using a cut-off of 6B. Among the lightweight LMMs, we further categorize them into three groups based on their model size. Within each group of the lightweight LMMs, the best result on each benchmark is bold.
Table 2. Comparison of our Imp models (with purple backgrounds) and open-sourced stateof-the-art LMMs on ten commonly-used VQA and LMM benchmarks. #PT and #FT denote the number of pretrainng and instruction-tuning samples, respectively. Benchmark names are abbreviated due to space limits: VQA-v2; GQA; VisWiz; SQAI: ScienceQA-IMG; VQAT: TextVQA; POPE; MMEP: MME-Perception; MMB: MMBench (dev); MMBCN: MMBench-Chinese (dev); MM-Vet . *: The training images of the datasets are observed during training. The compared LMMs are first categorized into the normal-sized and lightweight groups using a cut-off of 6B. Among the lightweight LMMs, we further categorize them into three groups based on their model size. Within each group of the lightweight LMMs, the best result on each benchmark is bold.
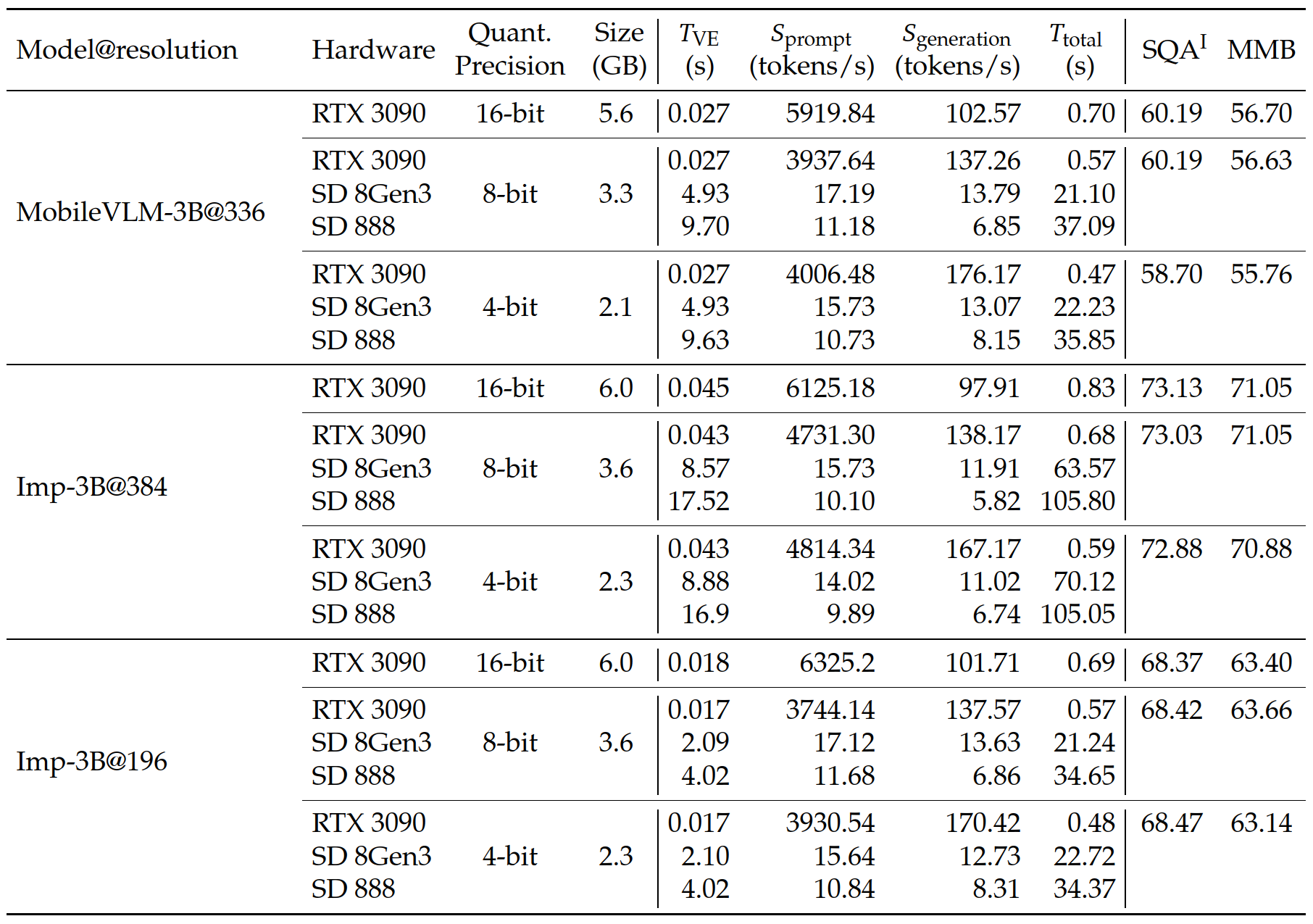 Table 3. Latency and performance comparisons of MobileVLM-3B@336, Imp-3B@384 and Imp-3B@196 on different hardware platforms and quantization precision. All models are evaluated using llama.cpp framework with 16/8/4-bit quantilization precision. SD denotes the Snapdragon mobile chip from Qualcomm. 𝑇VE indicates the visual encoding time. 𝑆prompt and 𝑆gen measure the speed (tokens/s) of the prompt encoding and response generation stages, repetitively. 𝑇total refers to the entire latency to infer one sample.
Table 3. Latency and performance comparisons of MobileVLM-3B@336, Imp-3B@384 and Imp-3B@196 on different hardware platforms and quantization precision. All models are evaluated using llama.cpp framework with 16/8/4-bit quantilization precision. SD denotes the Snapdragon mobile chip from Qualcomm. 𝑇VE indicates the visual encoding time. 𝑆prompt and 𝑆gen measure the speed (tokens/s) of the prompt encoding and response generation stages, repetitively. 𝑇total refers to the entire latency to infer one sample.
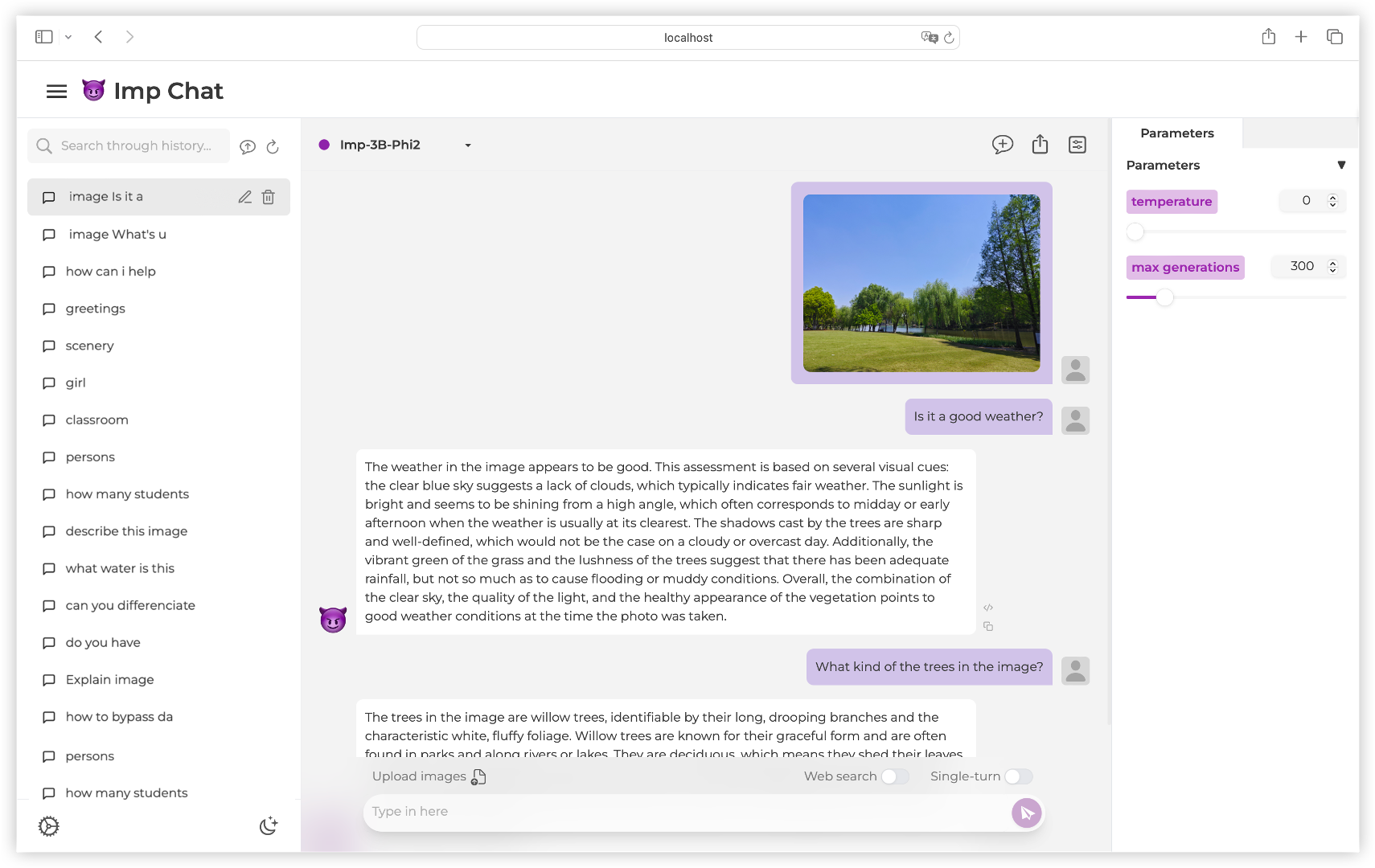
 Demonstrations of Diverse Skills
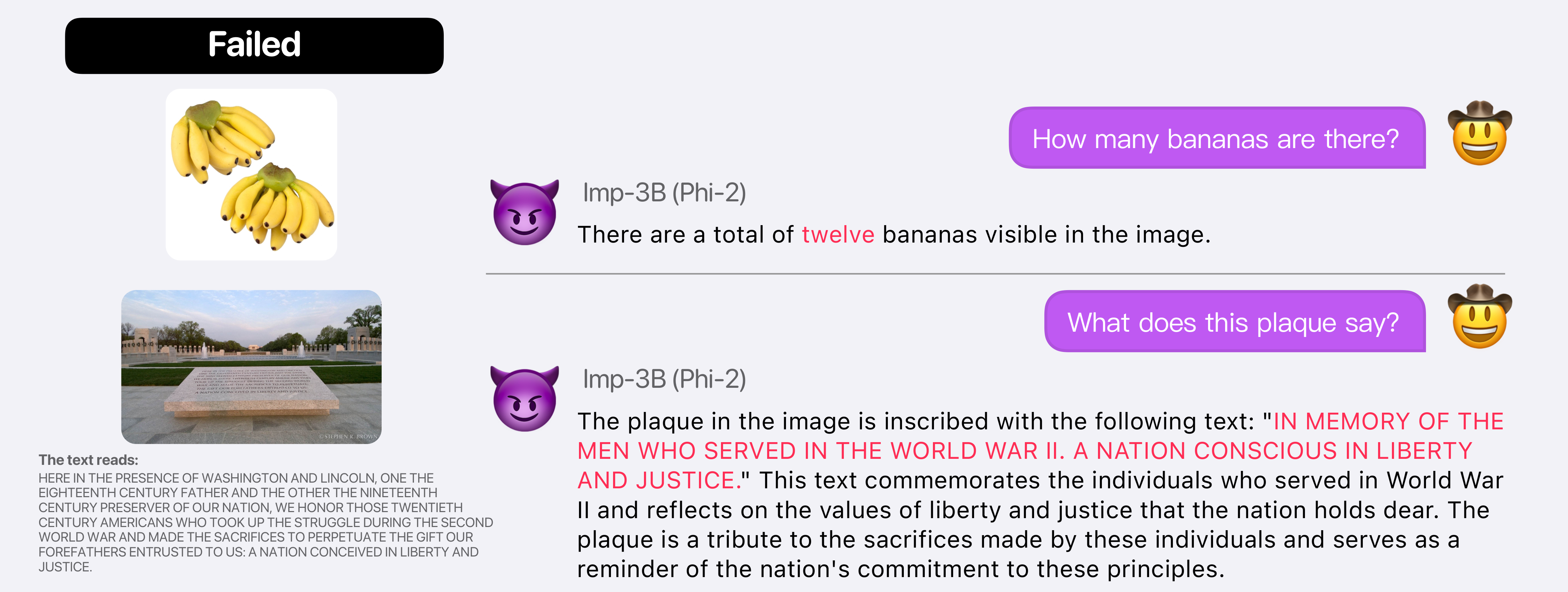
Demonstrations of Diverse Skills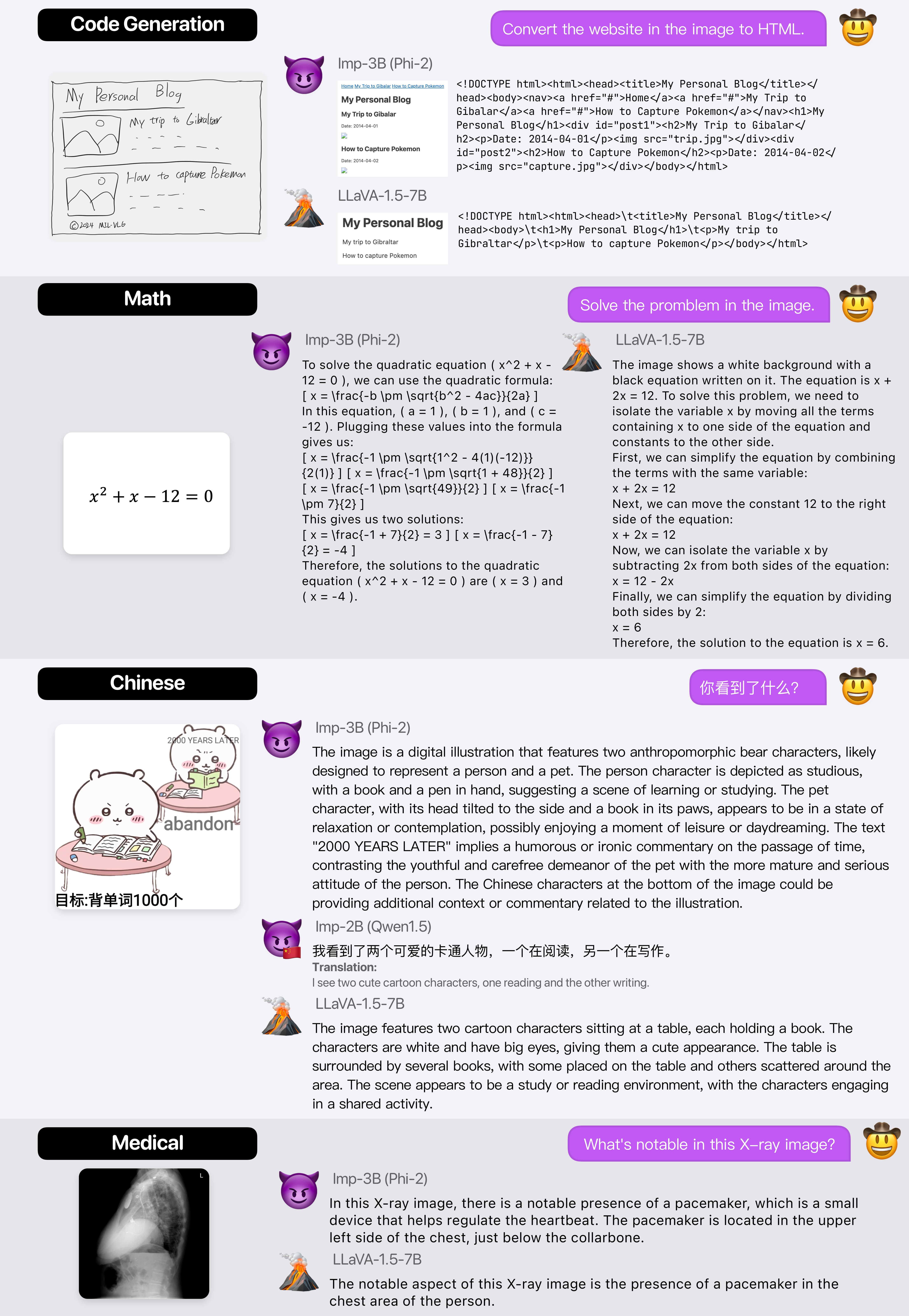

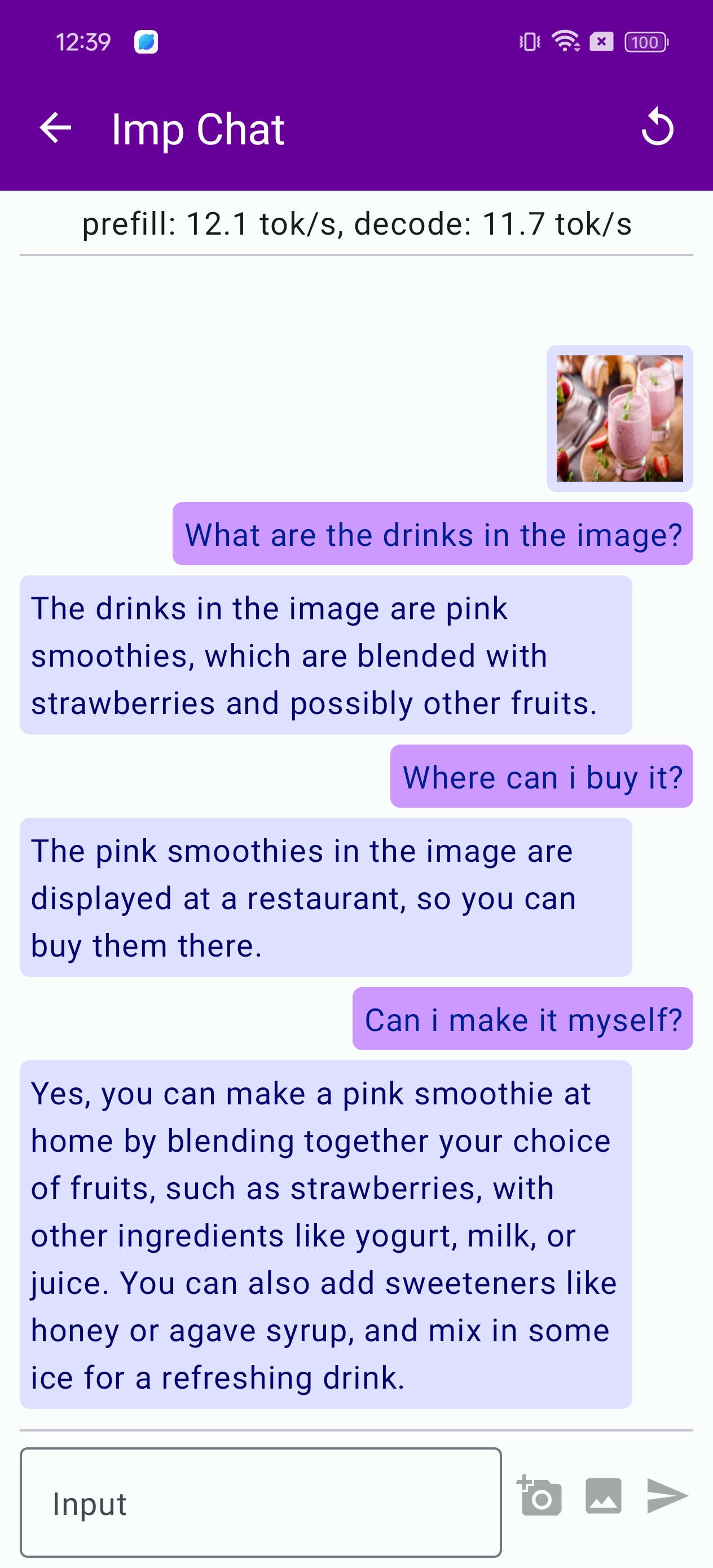
 ImpChat: LMM Assistants on Multiple Platforms
ImpChat: LMM Assistants on Multiple Platforms